Machine Learning

To refer to artificial intelligence, the term Machine Learning is also used. A lot of people confuse Machine Learning with artificial intelligence. In reality, artificial intelligence is nothing but a theoretical explanation of Machine learning, the former is a concept, and the latter is its practical implementation. We need to go back to its history to understand what Machine Learning is.
Alan Turing is well known for his contributions in the field of computing and technology. In 1950, he wrote an article named "Computing Machinery and Intelligence," he stated that these machines could be used to imitate a person's answers to certain questions in a certain environment. This theory and insight back in 1950 paved its way to becoming the foundation of machine learning and artificially intelligent approaches.

The term "Learning" comes from the advances made while at IBM by computer scientist Arthur Samuel. By taking a step towards self-learning computers, he believed that there is no need to program computers to learn a specific task; he wanted those machines or computers to learn without being programmed for that particular purpose. His main area of expertise was in computer games, where he showed the concept of artificial intelligence.
Tom M. Mitchell wrote a book called "Machine Learning" (McGraw-Hill, 2013) in which he described what the term machine learning meant to him. He said that machine learning is a computer program that learns from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with the experience E. It means that machine learning continuously improves P performance on task or tasks T to improve the experience E.
As far as the implementation is concerned, machine learning is based on certain algorithms that are able to learn from certain parameters passed in the form of data provided to the machine learning model.
A sample data set is given to our machine learning model on the basis of which it gets trained to perform predictions.
A simplified sample of data set for condition monitoring is as follows:
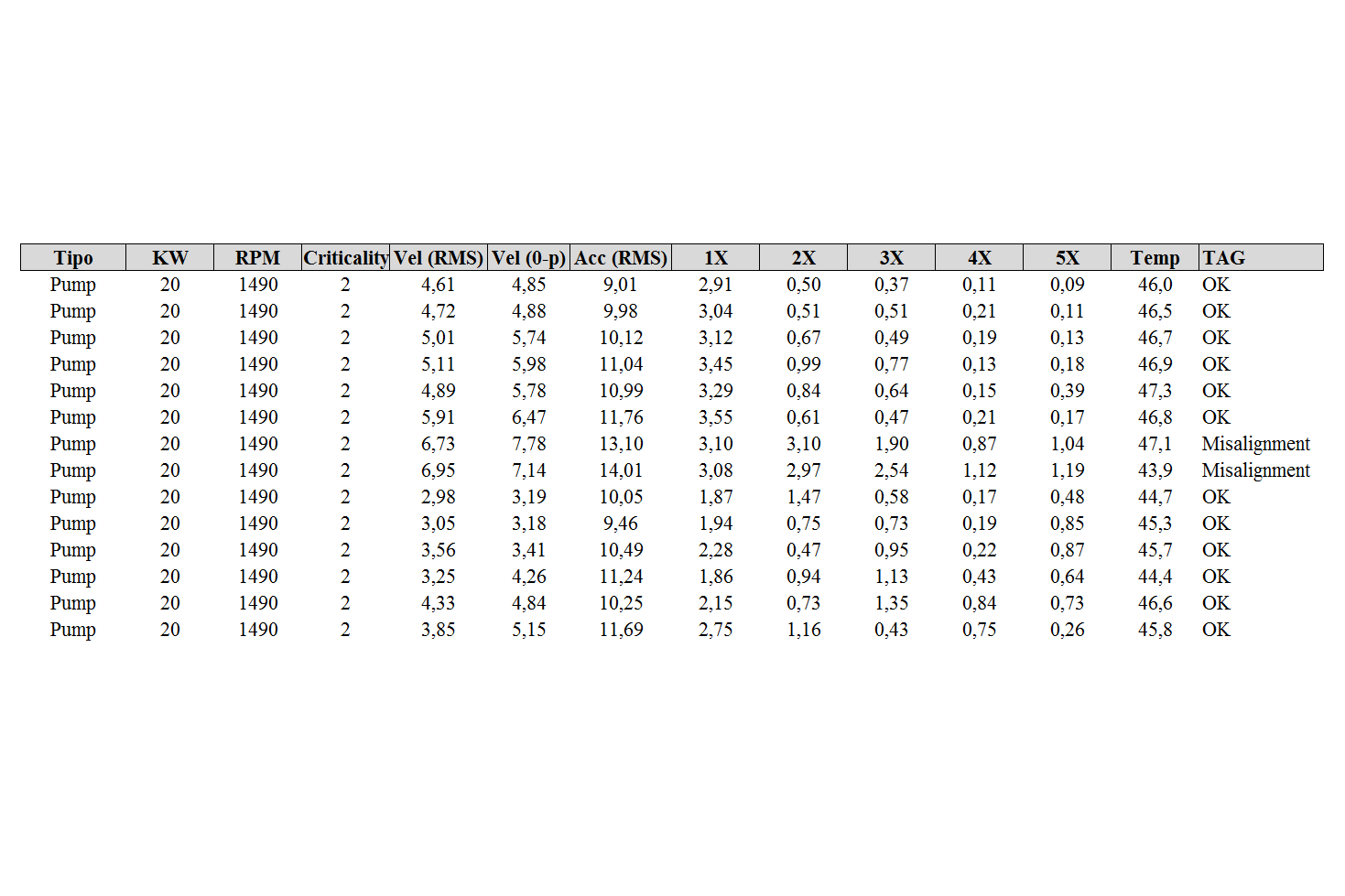 Machine learning can be classified into two major types. Supervised and unsupervised learning, here in the last column, you can see the TAG values that are basically the predictions generated from the given data.
Machine learning can be classified into two major types. Supervised and unsupervised learning, here in the last column, you can see the TAG values that are basically the predictions generated from the given data.
This TAG column differentiated between supervised and unsupervised models.
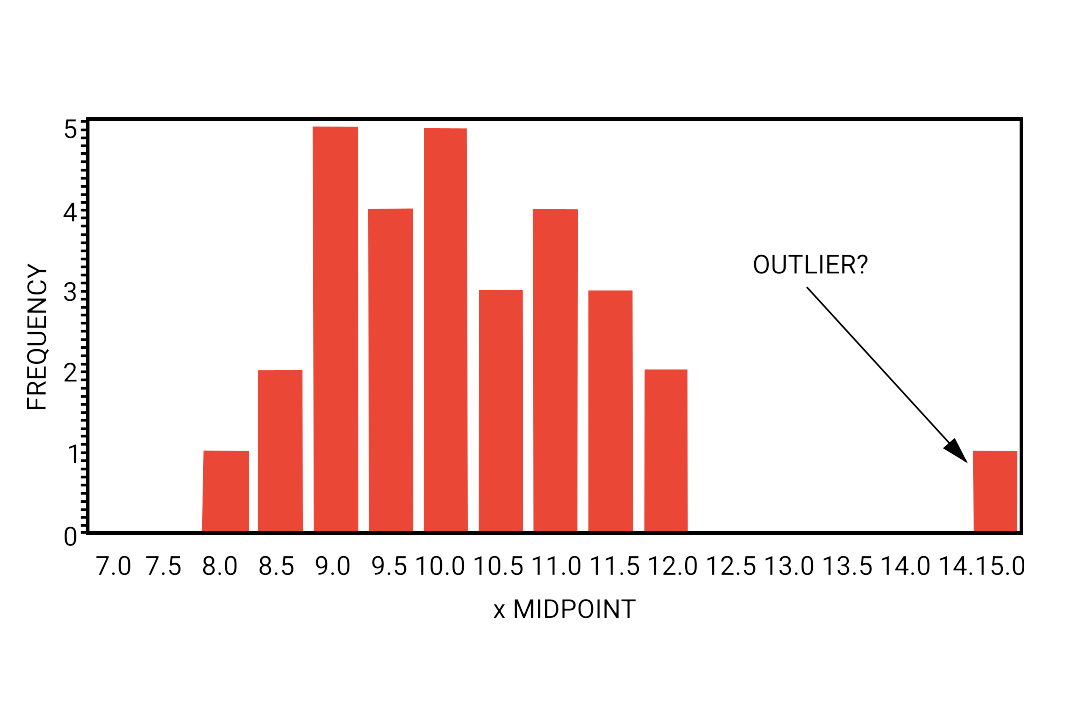
As seen in the data, only two tags are "Misalignment". Seeing the trends of data on these columns, one can see from naked eye that their values of various columns were certainly high compared to other engines. For small amounts of data, this can be done manually, but when considering a data set with thousands of entries, there is a need for a machine learning model.
These data points can be referred to as outliers. As you can see, they differ significantly from other values. An outlier is a statistical term, and one can say without any iota of doubt that statistics and machine learning goes hand in hand with each other.
 Supervised models have tags where you can see that it is either "OK" or "Misaligment", these labels come from the predictions our model made or from a vibration analyst. This tag is generated after considering various parameters, and each of the parameters has different importance in determining the tag of the machine's condition. A well-trained efficient model contains multiple parameters or independent variables. Here in the scenario, the tag is the dependent variable whose value is dependent on multiple factors on which our model is trained.
Supervised models have tags where you can see that it is either "OK" or "Misaligment", these labels come from the predictions our model made or from a vibration analyst. This tag is generated after considering various parameters, and each of the parameters has different importance in determining the tag of the machine's condition. A well-trained efficient model contains multiple parameters or independent variables. Here in the scenario, the tag is the dependent variable whose value is dependent on multiple factors on which our model is trained.
After the tags are generated, then other models determine the score of the model. A score here means how accurate our model was; the analyst enters the tag and checks whether it is true or false or something in between. This means that once the machine learning algorithm is implemented, it is essential to check its score before applying it to an autonomous diagnose tool. In this scenario, the concepts of accuracy, precision, recall, F1 score come into play that determine the validity of our model based on true positives, true negatives, false positives and false negatives.
What is Power-MI?
Power-MI is a cloud based solution that allows you to design & manage your condition-based maintenance plan integrating all techniques into one platform. Easy reporting, automatic work orders and CMMS integration.
Read more