Machine Learning

Para hacer referencia a la inteligencia artificial, también se utiliza el término Machine Learning. Mucha gente confunde el Machine Learning con la inteligencia artificial. En realidad, la inteligencia artificial no es más que una explicación teórica del Machine Learning, la primera es un concepto y la segunda es su implementación práctica. Necesitamos volver a su historia para entender qué es el Machine Learning.
Alan Turing es muy conocido por sus contribuciones en el campo de la informática y la tecnología. En 1950, escribió un artículo llamado "Computing Machinery and Intelligence", afirmó que estas máquinas podrían usarse para imitar las respuestas de una persona a ciertas preguntas en un entorno determinado. Esta teoría y conocimiento en 1950 allanó el camino para convertirse en la base del aprendizaje automático y los enfoques de inteligencia artificial.

El término "aprendizaje" (Learning) proviene de los avances realizados en IBM por el científico informático Arthur Samuel. Dando un paso hacia las computadoras de autoaprendizaje, creía que no era necesario programar las computadoras para aprender una tarea específica. Quería que esas máquinas o computadoras aprendieran sin estar programadas para ese propósito en particular. Su principal área de especialización fue en los juegos de computadora, donde mostró el concepto de inteligencia artificial.
Tom M. Mitchell escribió un libro llamado "Machine Learning" (McGraw-Hill, 2013) en el que describió lo que significaba para él el término aprendizaje automático. Dijo que el aprendizaje automático es un programa de computadora que aprende de la experiencia E con respecto a alguna clase de tareas T y medida de rendimiento P, si su rendimiento en las tareas T, medido por P, mejora con la experiencia E. Significa que la máquina de aprendizaje mejora continuamente P el desempeño en una tarea o tareas T para mejorar la experiencia E.
En lo que respecta a la implementación, el Machine Learning se basa en ciertos algoritmos que son capaces de aprender de ciertos parámetros que se pasan en forma de datos proporcionados al modelo de aprendizaje automático.
Se proporciona un conjunto de datos de muestra a nuestro modelo de aprendizaje automático sobre la base del cual se entrena para realizar predicciones.
Una muestra simplificada del conjunto de datos para el monitoreo de condiciones es la siguiente:
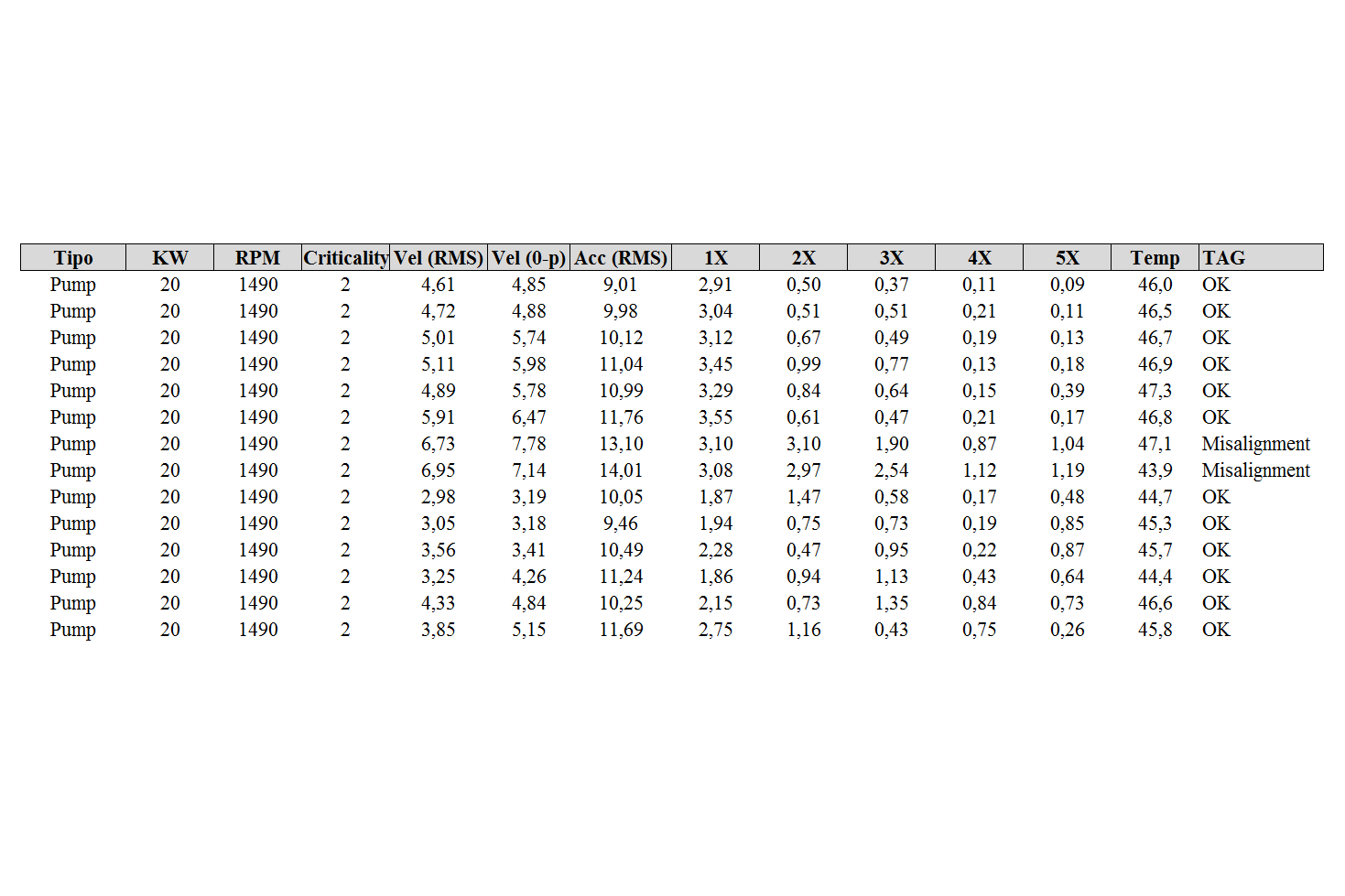 El Machine Learning se puede clasificar en dos tipos principales. Aprendizaje supervisado y no supervisado, aquí en la última columna, puede ver los valores de TAG que son básicamente las predicciones generadas a partir de los datos dados.
El Machine Learning se puede clasificar en dos tipos principales. Aprendizaje supervisado y no supervisado, aquí en la última columna, puede ver los valores de TAG que son básicamente las predicciones generadas a partir de los datos dados.
Esta columna TAG diferenciaba entre modelos supervisados y no supervisados.
Como se ve en los datos, solo dos etiquetas son "Desalineación". Al ver las tendencias de los datos en estas columnas, se puede ver a simple vista que sus valores de varias columnas eran ciertamente altos en comparación con otros motores. Para pequeñas cantidades de datos, esto se puede hacer manualmente, pero cuando se considera un conjunto de datos con miles de entradas, existe la necesidad de un modelo de aprendizaje automático.
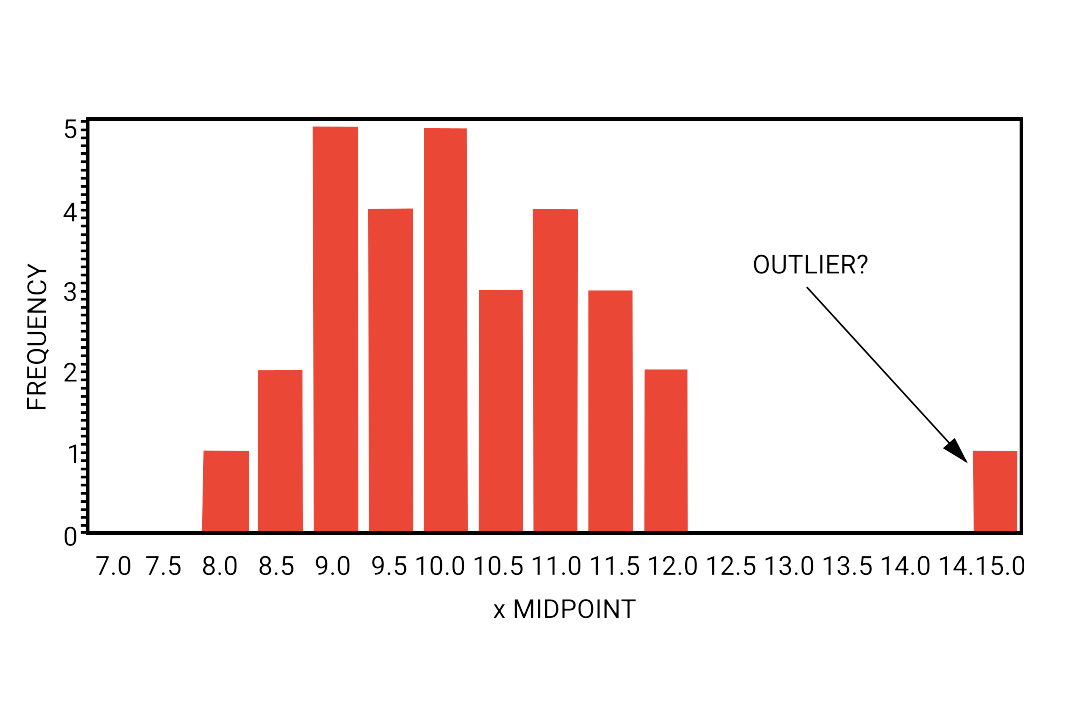
Estos puntos de datos pueden denominarse valores atípicos. Como puede ver, difieren significativamente de otros valores. Un valor atípico es un término estadístico, y se puede decir sin ningún ápice de duda que las estadísticas y el aprendizaje automático van de la mano.
Los modelos supervisados tienen etiquetas en las que puede ver que está "OK" o "Desalineación", estas etiquetas provienen de las predicciones que hizo nuestro modelo o de un analista de vibraciones. Esta etiqueta se genera después de considerar varios parámetros, y cada uno de los parámetros tiene una importancia diferente para determinar la etiqueta de la condición de la máquina. Un modelo eficiente bien entrenado contiene múltiples parámetros o variables independientes. Aquí en el escenario, la etiqueta es la variable dependiente cuyo valor depende de múltiples factores en los que se entrena nuestro modelo.
Una vez generadas las etiquetas, otros modelos determinan la puntuación del modelo. Una puntuación aquí significa la precisión de nuestro modelo; el analista ingresa la etiqueta y verifica si es verdadera o falsa o algo intermedio. Esto significa que una vez implementado el algoritmo de Machine Learning, es fundamental verificar su puntuación antes de aplicarlo a una herramienta de diagnóstico autónoma. En este escenario entran en juego los conceptos de exactitud, precisión, memoria, puntuación F1 para determinar la validez de nuestro modelo en base a verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos.
¿Qué es Power-MI?
Power-MI es una herramienta en la nube que le permite diseñar y gestionar su mantenimiento predictivo con todas las técnicas en una plataforma. Informes fáciles, órdenes de trabajo automáticas e integración a CMMS.
Leer más
Comentarios (2)
pHqghUme
Dom, 03/08/2025 - 15:28
pHqghUme
Dom, 03/08/2025 - 15:28